
Docker is a packaging and deployment system. It allows you to package an application as a “docker image“, then deploy it easily on some servers with a single “docker start <image>” command.
Packaging an application
Packaging an application without Docker

- A developer pushes a change
- The CI sees that new code is available. It rebuilds the project, runs the tests and generates a package
- The CI saves all files in”dist/*” as build artifacts
The application is available for download from “ci.internal.mycompany.com/<project>/<build-id>/dist/installer.zip”
Packaging an application with Docker
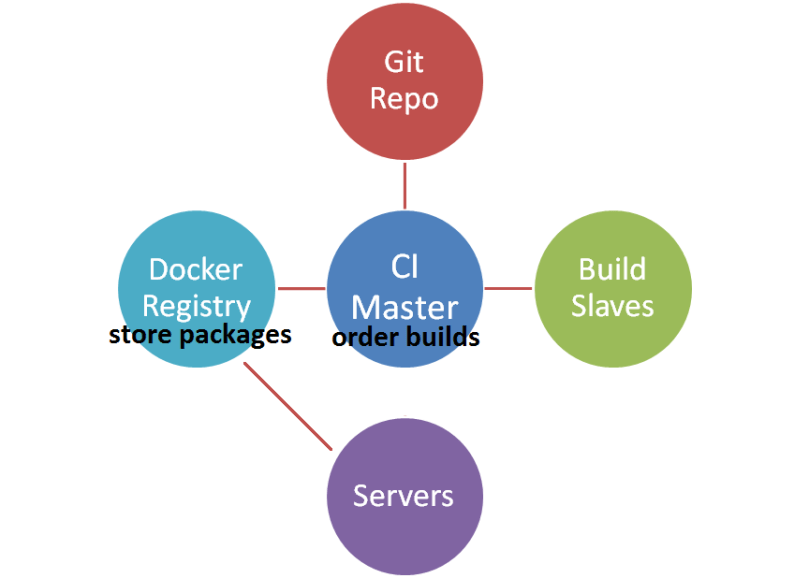
- A developer pushes a change
- The CI sees that new code is available it. It rebuilds the project, runs the tests and generates a docker image
- The docker image is saved to the docker registry
The application is available for download as a docker image named “auth:latest” from the registry “docker-registry.internal.mycompany.com”.
You need a CI pipeline
A CI pipeline requires a source code repository (GitLab, GitHub, VisualSVN Server) and a continuous integration system (Jenkins, GitLab CI, TeamCity). Docker also needs a docker registry.
A functional CI pipeline is a must-have for any software development project. It will ensure that your application(s) are automatically re-run, re-tested and re-packaged on every change.
The developers gotta write scripts to build their application, to run tests and to generate packages. Only the developers of an application can do that because they are the only ones to have the knowledge about how things are supposed/expected to work.
Generally speaking, the CI jobs should mostly consist into calling external scripts, like “./build.sh && ./tests.sh”. The scripts themselves must be part of the source code, they’ll evolve with the application.
You need to know your applications
Please answer the following questions:
- What does the application need to be built?
- What’s the command/script to build it?
- What does the application need to run?
- What configuration file is needed and where to put it?
- What’s the command to start/stop the application?
You need to be able to answer all these questions, for all the applications you’re writing and managing.
If you don’t know the answers, you have a problem and Docker is NOT the solution. You gotta figure out how things works and write documentation! (Better hope the guys who were in charge are still working here and gave a thought about all that).
If you know the answers, then you’re good. You know what has to be done. Whether it will be executed by bash, ansible, DockerFile, spec or zip is just an implementation detail.
Deploying an application
Deploying an application without Docker
- Download the application
- Setup dependencies, services and configuration files
- Start the application
# ansible pseudo code
hosts: hosts_auth
serial: 1 #rolling deploy, one server at a time
become: yes
tasks:
name: instance is removed from the load balancer
elb_instance:
elb_name: auth
instance_id: "{{ ansible_ansible_id }}"
state: absent
name: service is stopped
service:
name: auth
state: stopped
name: existing application is deleted
file:
path: /var/lib/auth/
match: "*"
recursive: yes
state: absent
name: application is deployed
unarchive:
url: https://ci.internal.mycompany.com/auth/last/artifacts/installer.zip
destination:: /var/lib/auth
name: virtualenv is setup
pip:
requirements: /var/lib/auth/requirements.txt
virtualenv: /var/lib/auth/.venv
name: application configuration is updated
template:
src: auth.conf
dst: /etc/mycompany/auth/auth.conf
name: service configuration is updated
template:
src: auth.service
dst: /etc/init.d/mycompany-auth
name: service is started
service:
name: auth
state: running
name: instance is added to the load balancer
elb_instance:
elb_name: auth
instance_id: "{{ ansible_ansible_id }}"
state: present
Deploying an application with Docker
- Create a configuration file
- Start the docker image with the configuration file
# ansible pseudo code
hosts: hosts_auth
serial: 1 #rolling deploy, one server at a time
become: yes
tasks:
name: instance is removed from the load balancer
elb_instance:
elb_name: auth
instance_id: "{{ ansible_ansible_id }}"
state: absent
name: container is stopped
docker:
name: auth
state: stopped
name: configuration is updated
template:
src: auth.conf
dst: /etc/mycompany/auth/auth.conf
name: container is started
docker:
name: auth
image: docker-registry.internal.mycompany.com/auth:latest
state: started
mount:
/etc/mycompany/auth/auth.conf:/etc/mycompany/auth/auth.conf
port:
8101:8101
name: instance is added to the load balancer
elb_instance:
elb_name: auth
instance_id: "{{ ansible_ansible_id }}"
state: present
Notable differences
With docker, the python setup/virtualenv and the service configuration is done during the image creation rather than during the deployment. (The commands are the same, they’re just done in an earlier build stage).
The configuration files are deployed on the host and mounted inside Docker. It would be possible to bake the configuration file into the image but some configurations might only be determined at deployment time and we’d rather not store secrets in the image.
Infrastructure
Docker is only a packaging and deployment tool.
Docker doesn’t handle auto scaling, it doesn’t have service discovery, it doesn’t reconfigure load balancers, it doesn’t move containers when servers fail.
Orchestration systems (notably Kubernetes) are supposed to help with that. Currently, they are quite experimental and very difficult to setup [beyond a proof of concept]. The lack of proper orchestration will limit Docker to only be a hype packaging & deployment tool for the foreseeable future.
Docker [even with Kubernetes] needs an existing environment to run, including servers and networks. It ain’t gonna install and configure itself either.
All of that has to be done manually. Order servers in the cloud. Create OS images with Packer. Configure VPC and networking with Terraform. Setup the servers and systems with Ansible. Install and deploy the applications (including docker images) with Ansible.
Cheat Sheet
- Figure out what is required and how to build the applications
- Write build, test and packaging scripts
- Document that in the README
- Setup a CI system
- Configure automatic builds after every change
- Figure out the application dependencies and how to run it
- Add that to the README
- Write deploy and setup scripts (with Ansible or Salt)
Conclusion
Packaging and deploying applications is a real and challenging job. A Debian package has some good practices and standards to follow whereas Docker comes with no good practices and no rules whatsoever. Docker is a [marketing] success in part because it gives the illusion that the task is easy, with a sense of coolness.
In practise though, it is hard and there is no way around it. You’ll have to figure out your needs and decide on a practical way to deploy and package your applications that will be tailored just for you. Docker is not the solution to the problem, it’s just a random tool among many others, that may or may not help you.
It’s fair to say that the docker ecosystem is infinitely complex and has a long learning curve. If you have neat applications with clear and limited dependencies, they should be relatively manageable and docker can’t make it any easier. On the contrary, it has the potential to make it harder.
Docker shines to package applications with complex messy dependencies (typical NodeJS and Ruby environments). The dependency hell is taken away from the host and moved into the image and the image creation scripts.
Docker is handsome for dev and test environments. It allows to run multiple applications easily on the same host, isolated from each other. Better yet, some applications have conflicting dependencies and would be impossible to run on a single host otherwise.
You should investigate a configuration management system (Ansible) if you don’t already have one. It will help you to manage, configure and setup [numerous] remote servers, à la SSH on steroid. It’s way more general and practical than Docker (and you’re gonna need it to install docker and deploy images anyway).
Reminder: In spite of the practical use cases, docker should be considered as a beta tool not quite ready for serious production.

Two points:
1. You don’t need any sort of special CI tool or pipelines or whatever. After doing all the dev work and testing and whatnot on your machine, you can build the production Docker image on your machine as well and then push it up to the Docker repo. If you can’t do the same tests on your workstation as a separate CI server can do, you probably need to fix your test environment. (That said, there will be cases where you need something special in the test environment that you can’t give to every developer, but you of course should make every effort to avoid that kind of thing.)
2. While Docker can kind of be used as a “I’ll just give everyone an image of my machine” system, it’s not designed towards “here’s a dump of my machine.” It’s really oriented towards building a fairly minimal machine configuration that includes just the exact packages etc. that you need and deploying that in an environment almost completely separated from the environment of the machine hosting the Docker container. That, of course, is a very good approach, and it’s along the same lines of what I used to do in pre-Docker days where I’d include not just the code but also any libraries where I wasn’t sure about the version on all hosts, all configuration (e.g.,
httpd.conf,php.conf), startup scripts, and so on. This would allow me both to quickly spin up a test environment on my machine (with ports and stuff parameterized to avoid conflicts with other web servers, test environments, or whatever) and use an almost identical startup configuration on production servers. Docker basically just lets you easily apply containers to the same idea.LikeLike
1. Right, you can build an image on a dev machine, and even push it to the registry.
For companies, the norm is to have a dedicated CI system that’s recompiling/testing/packaging the application on every change. It builds a new docker image on every change, tagged with the branch and commit id.
LikeLike
I know that having that is the norm, but it seems to me an utter waste of time for most applications, and even more so for those applications using Docker.
1.If the developer did a docker build, tested it, the tests were good, and pushed it up, the CI cluster will build a docker image with the same ID, pass the same tests, attempt to push it, and the server will say, “thanks, but I’ve already had that for ages.” No benefit at all.
2. If the tests broke on the CI cluster but not on the developer system, you have an environment issue that you need to fix. This calls more for a rethink of how you test things than simply running more tests on more different machines in the hope that one will have an environment different enough that it will find the environmental dependencies you’re putting into your code. Spend time reworking your ideas about how to test, not building CI clusters.
Beyond all this, every time your CI cluster catches an error, you should be asking yourself, “how did the error get that far?” i.e., how is it the developer wasn’t able to see the error when he was working on the code, rather than having to send it over to the CI cluster and wait for it to come back?
I hate to admit my age, but “write code, submit to remote machine, wait for list of errors” really feels like punched cards all over again. It’s not agile in the slightest.
LikeLike
You’re clearly missing the points of a CI.
1) It gives you the guarantee that everything is executed correctly every single time (unit tests, integration tests, packaging, dependencies…), and it keeps the history of all package versions, test status, failures, etc…
You can’t rely on the devs to run everything manually every time, they just won’t do it, and even if they did there is nothing left of it.
2) “write code, submit to remote machine, wait for list of errors” => It doesn’t [have to] work this way.
The devs can run stuff locally with the same scripts as the CI. They can execute whatever they want before they push.
3) There are builds & tests that may require specific resources and/or much time. You better have a shared central system for these. (Ever heard of C++ builds that take 1 hour on a local box but only 3 minutes on a distributed build cluster?)
LikeLike
Yes, I think I do kinda miss the point of a CI.
Let me address point 3, first. Yes, there are builds & tests that require extensive resources and can run much faster on a CI cluster. But in my experience, this is is true of a small minority of systems. For the majority of systems I’ve seen local testing can get your results about as fast or even faster (given the time it takes for the commit to get pushed up, the CI system to do the checkout, etc.) than the CI machines can. It’s all a matter of whether you’re willing to write the scripts to do it, and doing that is generally no harder (sometimes, even, easier) than writing similar scripts that can run only on the CI machines but not developer machines.
When local testing is too slow the first thing you should always be asking yourself is not “how can I put more stuff (such as making and pushing commits) between the developer and his tests” but instead “how can I make it faster and easier for the developer to run his tests right there and get feedback as soon as possible.”
Which brings me to point 1: Developers should not have to think, “Ok, all the tests passed on my machine, but that might not be correct; I’d best kick it off to do another run on a CI machine to see if the tests really passed.” If the CI machines can execute things correctly every single time but developers can’t, that, again, is something you should take a serious look at. Is it because it’s actually hard to do for humans, such as developers have to type in a long sequence of commands by hand? That should be automated. (On most of my systems you clone the repo,
cdinto its directory and type./TestThat’s it.) Or is it because developers don’t want to thoroughly test their code before pushing up commits? Willingness to have broken commits flying around is a culture program that I’d argue you should address.TLDR: There are indeed resource-hungry situations on huge projects where a CI cluster can be a big help. But for most projects separate CI machines are neither necessary nor desirable; they’re either doing nothing terribly useful or they’re covering up very serious problems with developer discipline (devs are deliberately submitting under-tested commits) or your test framework.
LikeLike
I know that having that is the norm, but it seems to me an utter waste of time for most applications, and even more so for those applications using Docker.
1.If the developer did a docker build, tested it, the tests were good, and pushed it up, the CI cluster will build a docker image with the same ID, pass the same tests, attempt to push it, and the server will say, “thanks, but I’ve already had that for ages.” No benefit at all.
2. If the tests broke on the CI cluster but not on the developer system, you have an environment issue that you need to fix. This calls more for a rethink of how you test things than simply running more tests on more different machines in the hope that one will have an environment different enough that it will find the environmental dependencies you’re putting into your code. Spend time reworking your ideas about how to test, not building CI clusters.
Beyond all this, every time your CI cluster catches an error, you should be asking yourself, “how did the error get that far?” i.e., how is it the developer wasn’t able to see the error when he was working on the code, rather than having to send it over to the CI cluster and wait for it to come back?
I hate to admit my age, but “write code, submit to remote machine, wait for list of errors” really feels like punched cards all over again. It’s not agile in the slightest.
LikeLike
[…] How to deploy an application with Docker… and without Docker, An introduction to application deployment, The HFT Guy. […]
LikeLike