
TL;DR This doesn’t mean that the scheduler can’t use more than 8 cores. The scheduler controls how to allocate tasks to available cores. How to schedule particular workloads efficiently on available hardware is a complex problem. There are settings and hardcoded timings to control the behavior of the scheduler, some vary with the number of cores, some don’t, unfortunately they don’t work as intended because they were capped to 8 cores. This had a rationale around 2005-2010 when the latest CPUs were the core 2 duo and core 2 quad on interactive desktops and “nobody will ever get more than 8 cores”, this doesn’t hold as well in 2023 when the baseline is 128 cores per CPU on non-interactive servers.
TL;DR; Yes, this has performance implications especially if you run compute clusters, no, your computer won’t get 20 times faster. Sorry. Either way, comments in the kernel, man pages and sysctl documentation are wrong and should be corrected, they genuinely missed for the last 15 years that there was a scaling factor at play capped to 8 cores.
A bit of history
I’ve been diving into the Linux kernel scheduler recently.
To give a short brief introduction to scheduling, imagine a single CPU single core system. The operating system allocates time slices of a few milliseconds to run applications. If every application can get a few milliseconds now and then, the system feels interactive, to the user it feels like the computer is running hundreds of tasks while the computer is only running 1 single task at any time.
Then multi core systems became affordable for consumers in the early 2000s, most computers got 2 or 4 cores and the operating system could run multiple tasks in parallel for real. That changed things a bit but not too much, server could already have multi 2 or 4 physical CPUs in a server.
The number of cores increased over time and we’ve reached a state in early 2020s where the baseline is AMD servers with 128 cores per CPU.
For the anecdote, historically on windows the period was around 16 milliseconds, it had a funny side effect where an application doing a sleep(1ms) would resume around 16 milliseconds later.
Linux Scheduler
Back to Linux, short and simplified version.
On Linux the kernel scheduler works in periods of 5 milliseconds (or 20 milliseconds on multicore systems) to ensure that every application has a chance to run in the next 5 milliseconds. A thread that takes more than 5 milliseconds is supposed to be pre-empted.
It’s important for end user latency. In layman terms, when you move you mouse around AND the mouse is moving on the screen at least every few milliseconds, the computer feels responsive and it’s great. That’s why the Linux kernel was hardcoded to 5 milliseconds forever ago, to give a good experience to interactive desktop users.
It’s intuitive enough that the behavior of the scheduler had to change when CPU got multiple cores. There is no need to aggressively interrupt tasks all the time to run something else, when there are multiple CPUs to work with.
It’s a balancing act. You don’t want to reschedule tasks every few milliseconds to another core, because it’s stopping the task and causing context switches and breaking caches, making all tasks slower, but you have to keep things responsive, especially if it’s a desktop with an end user, is it a desktop though?
The scheduler can be tuned with sysctl settings. There are many settings available, see this article for an intro but know that all scaling numbers are wrong since the kernel was accidentally hardcoded to 8 cores https://dev.to/satorutakeuchi/the-linux-s-sysctl-parameters-about-process-scheduler-1dh5
- sched_latency_ns
- sched_min_granularity_ns (renamed to base_slice in kernel v6)
- wakeup_granularity_ns
Commits
This commit added automated scaling of scheduler settings with the number of cores in 2009.
It was accidentally hardcoded to a maximum of 8 cores. Oops. The magic value comes from an older commit and remained as it was. Please refer to the full diff on GitHub.
https://github.com/torvalds/linux/commit/acb4a848da821a095ae9e4d8b22ae2d9633ba5cd
An interesting setting is the minimum granularity, this is supposed to allow tasks to run for a minimum amount of 0.75 milliseconds (or 3 ms in multicore systems) when the system is overloaded (there are more tasks to run in the period than there are CPU available).
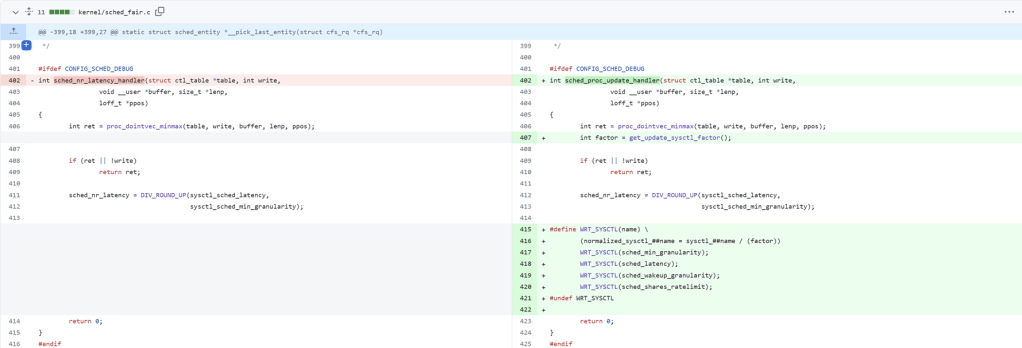
The min_granularity setting was renamed to base_slice in this commit in v6 kernel.
The comment says it scales with CPU count and the comment is incorrect. I wonder whether kernel developers are aware of that mistake as they are rewriting the scheduler!
- Official comments in the code says it’s scaling with log2(1+cores) but it doesn’t.
- All the comments in the code are incorrect.
- Official documentation and man pages are incorrect.
- Every blog article, stack overflow answer and guide ever published about the scheduler is incorrect.
https://github.com/torvalds/linux/commit/e4ec3318a17f5dcf11bc23b2d2c1da4c1c5bb507

Below is the function that does the scaling. This is the code where it’s been hardcoded to a maximum of 8 cores.
The maximum scaling factor is 4 on multi core systems: 1+log2(min(cores, 8)).
The default is to use log scaling, you can adjust kernel settings to use linear scaling instead but it’s broken too, capped to 8 cores.
https://github.com/torvalds/linux/blame/master/kernel/sched/fair.c#L198

Recent AMD desktop have 32 threads, recent AMD servers have 128 threads per CPU and often have multiple physical CPUs.
It’s problematic that the kernel was hardcoded to a maximum of 8 cores (scaling factor of 4). It can’t be good to reschedule hundreds of tasks every few milliseconds, maybe on a different core, maybe on a different die. It can’t be good for performance and cache locality.
To conclude, the kernel has been accidentally hardcoded to 8 cores for the past 15 years and nobody noticed.
Oops. ¯\_(ツ)_/¯


I’ve filed a bug upstream to track this https://bugzilla.kernel.org/show_bug.cgi?id=218144
LikeLike
The comments in the kernel are misleading or straight up wrong, but the code isn’t. The time slices are limited to scale with up to 8 cores, to not get huge time slices for tons of cores, but the scheduler itself can handle as many cores as the system has.
LikeLike
The 8 core limit only applies to scaling of the time slices.
LikeLike
Quite a find. Have you opened a bug, got a link to the bug?
LikeLike
Your headline does not correctly describe the behavior you describe. Which is a shame because it may be an important finding.
But then “Linux Scheduler Optimized For 8 Cores” doesn’t sell as well.
LikeLike
Whoa, this is surprising!
Have you tried removing the limit and benchmarking it? I am curious how much performance we are leaving on the table from that bug, but I don’t have any high core count machines.
LikeLike
This code is related only to the granularity time, increasing the number of CPUs would only allow tasks to run longer in a certain core, which is not the result you might want, since other tasks also want to run in that same core and would be stalled for more time. As you well pointed, is an act of balancing things, and having 8 as maximum number of CPUs for that specific calculation seems to still be a fine choice. Maybe a new benchmark would suggest another ceiling? Maybe. But that’s definitely not related to how many cores the scheduler see/use/consider/…
Check what Peter Zijlstra replied to this exact subject a few years ago:
https://lore.kernel.org/all/20211102160402.GX174703@worktop.programming.kicks-ass.net/
LikeLike
Very interesting article! Thanks for sharing. This may be unrelated to your discovery, however on 23rd June 2021 I noticed that Linux (Ubuntu) multiprocessing times per number of CPUs enabled posed an anomaly … whereas Windows acted as (I) expected. My (rather amateur) finding is posted on github here: https://github.com/skyfielders/python-skyfield/issues/612
My complaint about Linux is expressed near the following quoted text:
“Windows processing for a Nautical Almanac would then consume a maximum of 2 x 9 = 18 seconds. True! Windows processing of Event Time Tables would then consume a maximum of 2 x 16.5 seconds. True! But if you look at the Ubuntu times, this is NOT the case… which implies that something else is going on… interrupting the supposedly parallel processes. Very strange.”
LikeLike
As discussed on the Hacker News thread for this article[0], the title and conclusion of this article are incorrect and seem to be based on a misunderstanding.
What is capped to 8 is a scaling factor for the interval at which the scheduler switches tasks on any given core. Not the amount of cores the system can actually work with.
As correctly stated in this article, the fewer cores you have the quicker those cores need to switch between tasks to maintain fluid, interactive “feel” for the user and to maintain performance across multiple running programs. However, as the core count increases from 8 to 16 to 128 and more, as some modern servers may have, you actually don’t want to continue increasing that interval factor – you don’t want individual cores bound to a single task for whole seconds! Especially when those machines are under high load, that would probably lead to reduced performance.
In fact, the comment currently visible in the last screenshot used in this article states “but the relationship is not linear, so pick a second-best guess”.
[0] https://news.ycombinator.com/item?id=38260935
LikeLiked by 1 person
I liked the find and the background. Good research. Wish there were some conclusions, or theories, drawn about the performance impacts, though.
As an aside, I’m seeing a lot of articles these days that repeat the same thing over and over, almost like they’re a compilation of mini articles on the same topic, this article (loosely) included. ChatGPT?
LikeLike
written by hand
LikeLike
[…] pointed out from the The HTF Guy websitethe planner of the linux kernel has been encoded rigidly by mistake to a maximum of 8 cores and, […]
LikeLike