
We’re going to talk about advanced performance optimization in Python.
Let’s say we are processing numerous small json objects in an application.
Each object looks like this:
'link_product': '/product/id/222.product_name',
'id_product': '222',
'description': 'a very long description goes there. can be a thousand characters.',
'og:type': 'product',
'og:title': 'summary goes there',
'manufacturers': ['firstcompany', 'secondcompany'],
'link_manufacturers': ['/manufacturer/id/10732', '/manufacturer/id/2797'],
'languages': ['English', Japanese', 'Italian', 'German', 'Chinese', 'Spanish'],
'id_per_language: {
'English': '222',
'Spanish': '55876',
'Italian': '99931',
'German': '40582'
'Japanese': '24958',
'Chinese': '70561'
}
'images': ['https://ham.cdn.example.com/assets/compressedphoto/4864138.jpg']
'thumbnail': 'https://nun.cdn.example.com/assets/compressedphoto/848648/256x256.jpg'
... another ten fields.
Typical product information like you’ve seen a thousand times. There are many products and the data is de normalized.
Problem
On a sample dataset. The process reaches 3 GB of memory usage, while loading and parsing the dataset. It gets down to 1GB of memory after some processing and can run permanently there.
Problem: It’s too much memory. It doesn’t run well on the development machine or the future hosting.
The solution is to optimize. How could it be optimized?
String Deduplication
Looking at the data, there is a fair amount of repetition.
- The keys, the languages, the manufacturer names are all repeated a bazillion times.
- Most of the identifiers and links are repeated as well, a few times.
A string object has an overhead around 50 bytes, in addition to the text value itself. Memory usage can quickly add up when processing millions of small strings.
Assuming every string is creating its own object, a fair bit of memory could be saved if it were possible to deduplicate the string objects?
How to deduplicate string objects in Python?
Python supports string deduplication out-of-the box. Namely string interning, see sys.intern in python 3.
The interpreter is automatically interning strings in some circumstances. Mainly string constants in python scripts (line variable="hello world"), function/class names (for efficient lookup), or very small strings (single character).
Refer to python documentation (if only it were documented ahah!).
Example below. id() returns the address of a python object.
a = "hello"
b = "world"
u = a + b
v = "helloworld"
id(a + b) # 2709093338800
id("helloworld") # 2709093338736
id(u) # 2709093338608
id(v) # 2709093338736
id(sys.intern(a + b)) # 2709093338736
id(sys.intern("helloworld")) # 2709093338736
id(sys.intern(u)) # 2709093338736
id(sys.intern(v)) # 2709093338736
Python interned the "helloworld" string in the script as a unique object but not the constructed string a+b.
Note that it’s difficult and unintuitive to test interning because the interpreter is actively working against you, interning script content before execution (and statements entered manually when in the interpreter).
Usage
Let’s benchmark a small dataset coming from a json file. The file is 1000 MB (compact json encoding) with 200k records.
The built-in json parser can be given extra arguments to control how objects are instantiated.
Ever wondered why the json decoder has a crazy amount of magical arguments? json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw) that is for crazy people to do crazy performance optimizations.
Code:
###
obj = json.load(handle)
### VS
obj = json.load(handle, object_pairs_hook=deduplicate_keys)
### VS
obj = json.load(handle, object_pairs_hook=deduplicate_strings)
def deduplicate_keys(items):
return dict((sys.intern(k), v) for k, v in items)
def deduplicate_strings(items):
dct = dict()
for k, v in items:
if isinstance(v, list):
dct[sys.intern(k)] = [sys.intern(s) for s in v]
elif isinstance(v, str):
if len(v) < 80:
dct[sys.intern(k)] = sys.intern(v)
else:
dct[sys.intern(k)] = v
else:
dct[sys.intern(k)] = v
return dct
# to measure heap usage
# pip install guppy 3
import guppy
heap = guppy.hpy()
heap.setrelheap() # ignore existing objects
do_something()
print(heap.heap())
The above can do three things:
- intern dictionary keys (keys are always repeated)
- intern short strings, 80 characters maximum (identifiers and short links)
- intern lists of strings (notably list of languages and manufacturers)
Result

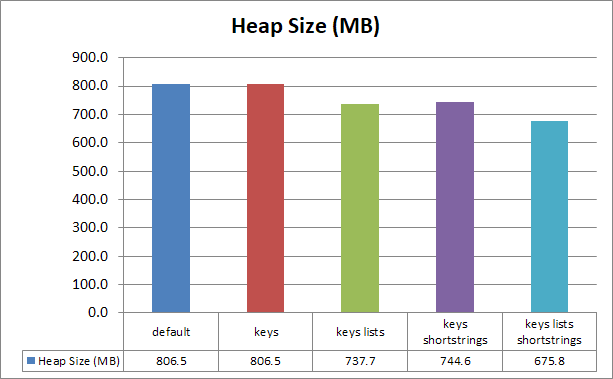


Good savings from interning strings. Memory usage goes down from 806 MB to 675 MB (that’s 17% for minimal changes). Interestingly more than half of the heap is consumed by strings.
The amount of objects is cut by 38% overall. That ought to have nice side effects like making allocation or garbage collection faster.
Another nice side effect is to make comparison and hash lookup faster. object==otherobject is instantaneous O(1) if both variables are referring to the same object (special case optimization), whereas the normal case is to do a character by character comparison O(N) going through the two strings.
Last but not least, interning dictionary keys alone made no difference at all. Python is automatically interning dictionary keys.
